기술자료
기술자료
컴파일러에서 사용하는 정적 분석 기술

컴파일러란?
소스 코드의 규모가 커지고 복잡해짐에 따라, 컴퓨터는 기계어 대신 사람이 이해하기 쉬운 고급 언어로 프로그램을 작성하게 되었습니다. 그러나 컴퓨터가 이 고급 언어를 이해하려면 다시 기계어로 변환하는 과정이 필요하며, 이 과정을 바로 컴파일(Compile)이라고 합니다.
컴파일은 4가지 단계(전처리 → 컴파일 → 어셈블리 → 링킹)로 진행됩니다. 그중 컴파일 과정은 전처리 소스 코드 파일(.i)을 어셈블리어 파일(.s)로 변환하는 과정으로, 정적 분석 기술을 통해 언어에 대한 문법 검사와 코드 분석이 이루어집니다.
이번 포스팅에서는 컴파일러에서 사용되는 '정적 분석 기술'에 대해 이야기하고자 합니다.
컴파일러 변환 과정
컴파일러는 전처리된 소스 코드 파일을 어셈블리어 파일로 변환하는 역할을 합니다. 변환 과정은 아래 <그림 1>과 같이 6단계로 진행됩니다.
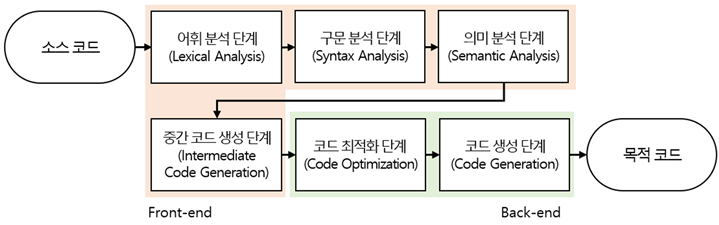
<그림 1> 컴파일러의 프론트엔드 및 백엔드 단계 흐름
1. 어휘 분석: 원시 프로그램의 어휘를 분리해 검사
2. 구문 분석: 문장 구조의 적합성 확인
3. 의미 분석: 코드의 의미와 기능 분석
4. 중간 코드 생성: 구문 분석 결과를 바탕으로 코드 생성
5. 코드 최적화: 불필요한 코드 제거 및 효율화
6. 코드 생성: 최종 기계어 코드 생성
프론트엔드(front-end)는 언어 종속적인 부분을 처리하며, 이때 정적 분석 기술이 활용됩니다. 정적 분석은 코드를 실행하지 않고 그 속성과 동작을 분석하는 기술입니다. 그럼 지금부터 컴파일러에서 정적 분석 기술이 어떻게 사용되는지 자세히 살펴보겠습니다.
어휘 분석
어휘 분석 단계는 프로그램의 소스 코드를 읽어 어휘라는 최소 단위로 나누는 과정입니다. 어휘 분석기는 소스 코드를 스캔하여 토큰(Token)으로 분리합니다. 토큰은 변수, 상수, 연산자, 구분자와 같은 언어 요소를 나타냅니다.
예를 들어, 식별자(identifier)는 변수명 ‘x1’이나 함수명 ‘printf’와 같이 이름을 나타내고, 예약어(reserved word)는 언어 자체에 정의된 토큰으로, 'if', 'for' 같은 조건문과 반복문이 이에 포함됩니다.
다음과 같은 수식을 어휘 분석 단계에서 처리한다고 가정해 보겠습니다.
위 수식은 곱셈 연산자(*), 덧셈 연산자(+), 변수(A, B), 상수(1)로 구성되어 있습니다. 어휘 분석기는 이 수식을 토큰으로 분리하여 'A, *, B, +, 1'과 같은 단위로 나눕니다. 이렇게 나눠진 토큰들은 구문 분석 단계로 전달되어 다음 과정을 진행합니다.
(후략)
* 위의 글은 슈어소프트테크에서 제공되었습니다.